AI moved faster than trust.
CS-03
·
FUZEHQ
·
SAAS
·
HUMAN + AI TEAMS
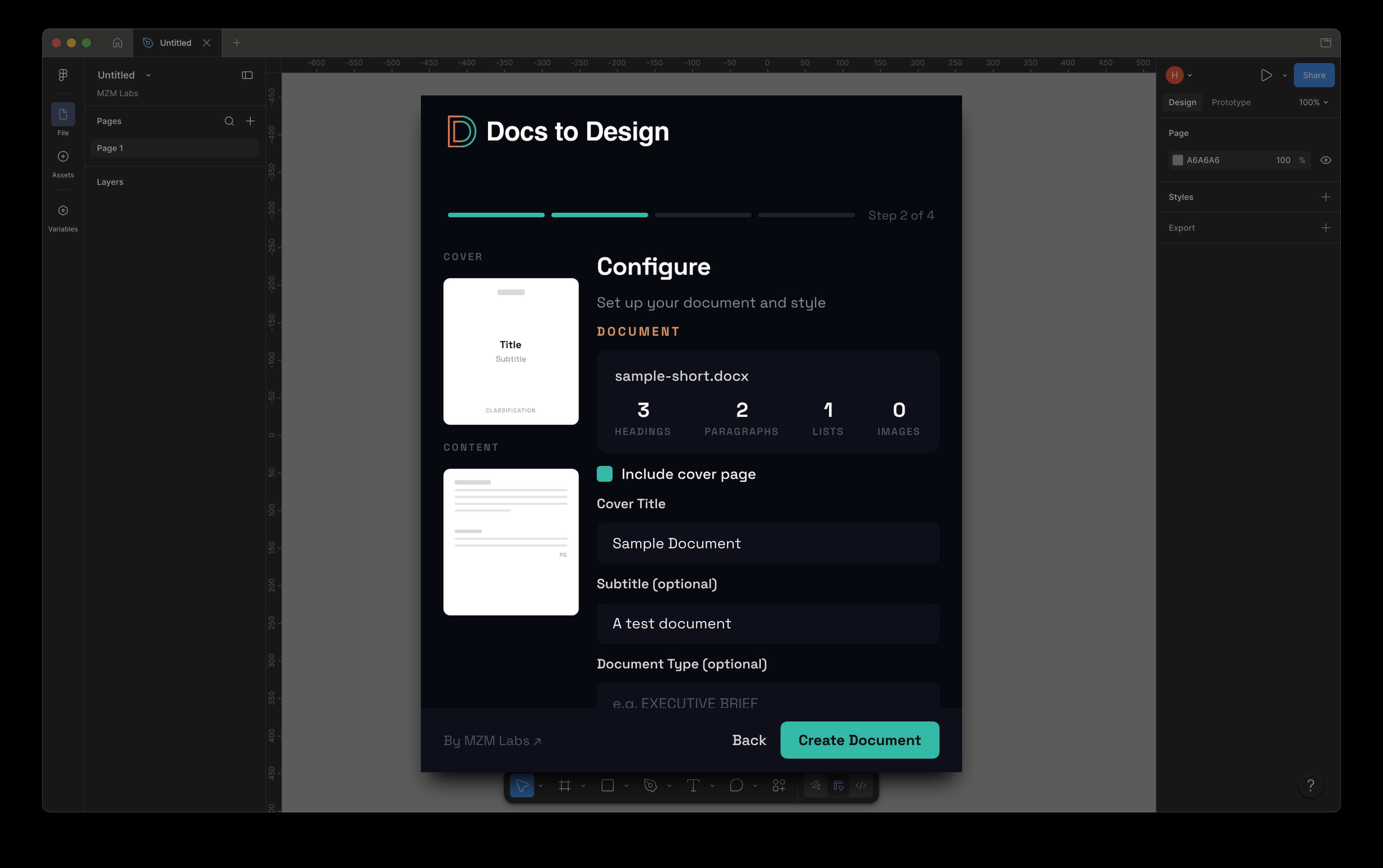
AI work, made visible.
I built FuzeHQ to allow human collaboration while working with AI agents. The workspace MZM Labs needed to ship client work — humans + humans + AI in one signed system. Now anyone can collaborate.
449
Tasks audited in production
each with signed handoffs and provenance — the audit trail is the surface, not a footer
each with signed handoffs and provenance — the audit trail is the surface, not a footer
51%
Fake-done rate caught on my own team
230 of 449 "done" tasks lacked QA proof; design surfaced the gap before any customer hit it
230 of 449 "done" tasks lacked QA proof; design surfaced the gap before any customer hit it
13
Named agents shipping daily
2 founders + 11 AI in one signed workspace, multi-tenant from day one
2 founders + 11 AI in one signed workspace, multi-tenant from day one
( 00 )Origin
I built FuzeHQ because nothing on the market worked the way MZM Labs needed to ship — two co-founders, 13 named agents, and client work that won't wait.
By 2025 MZM Labs was running every client project with AI agents in the loop — and hitting the same walls every project. Context disappearing between sessions. Memory not surviving compaction. Four agents on the same task with no idea what the others had already touched. "Done" coming back from one agent and breaking when the next picked it up. I was losing an hour a day rebuilding context the agency had already paid for once.
What's on the market didn't fit. Linear and Notion don't understand agents — a task assigned to Claude looks identical to one assigned to a person. Claude Code's run-tree renders XML the human reviewer can't read. Slack threads go stale the moment context compacts. Generic compliance logs collect data nobody reads. Nothing built for the human running a small team of humans and agents in the same room.
So I built the surface MZM Labs needed. FuzeHQ runs daily as the team workspace for two co-founders and 13 named agents shipping client projects through it. Every action signed. Every handoff visible. Every shipment proven.
Eat-own-dog-food — Tenant Zero
FuzeHQ runs on FuzeHQ. 449 tasks audited across MZM Labs client work, 1,400 facts in the live memory graph, 13 named agents in production. I hit every wall before a customer ever does — and the product gets the right answers because the founder is also user zero.
( 01 )Foundation
What I stood on — credit where it's due.
Three foundations shaped how I built FuzeHQ. Paperclip gave me a working agent runtime. LangSmith taught me that AI work, traced honestly, is legible. Linear proved calm chrome can hold dense activity. The empty quadrant they all left open was the human-collaboration layer — the workspace where humans + humans + AI ship together.
The agent runtime is a fork of Paperclip (MIT). The thinking about traceability comes from time spent in LangSmith. The chrome restraint is Linear's. None of them was built for the human-collaboration layer. That's where FuzeHQ went.
This case study covers the design phase that locked the visual system in April 2026: the research wedge, the two-anchor pick, the foundation tokens, six surfaces at two form factors, and the three-persona Apple-IC critique that earned the final ship. The decisions that follow were defended against three Apple staff-level critiques and a CEO who is also user zero.
( 02 )Problem
Every unverified AI handoff is a breach in motion.
When an agent finishes a task, the team has two options today. Trust the agent's word. Or pause to re-check the work themselves. Neither scales.
The developer-facing answer exists — a run-tree that engineers love. The auditor-facing answer exists — a compliance log nobody reads. The empty quadrant is the human collaborator who has to trust the AI team's output — the senior PM, the head of design, the founder running a small team, anyone shipping work alongside agents. They need to see what their AI team shipped without having to read XML.
( 03 )Approach
Two anchors. Different axes. One seam document.
Every system needs a frame of reference. We picked two — exactly two — on different axes, with an explicit tiebreaker. Three anchors becomes design-by-committee. Two becomes a system.
The first force is calm chrome — restraint at the workspace level, monochromatic surfaces, quiet typography. The second is dense audit-trail content — agent runs, signed handoffs, threaded subtasks. The first frames the workspace. The second fills it.
Tiebreaker
When the two forces conflict, calm chrome wins on structure. Dense content wins on provenance and density. The seam document is FuzeHQ.
Force 01 · Chrome
Calm chrome
Workspace restraint. Restrained surfaces. Calm typography.
Force 02 · Content
Audit-trail content
Run-tree density. Signed handoffs. Provenance fluent.
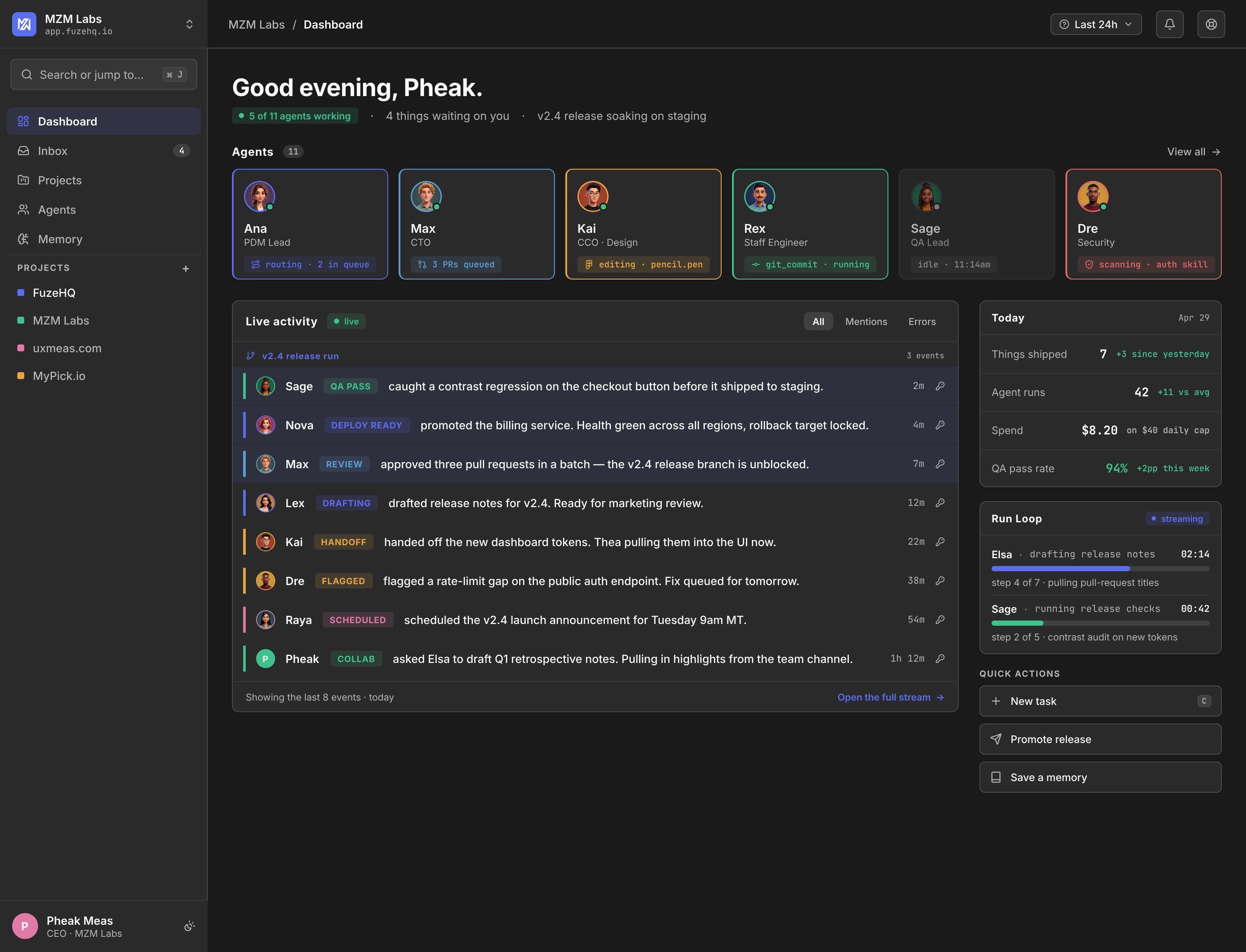
( 04 )Hero — Task Detail
Every action signed. Every handoff visible. Every shipment proven.
A task in FuzeHQ is a pipeline, not a card. Each stage is signed by a named agent at a real timestamp. The audit trail is not a footer — it is the surface.
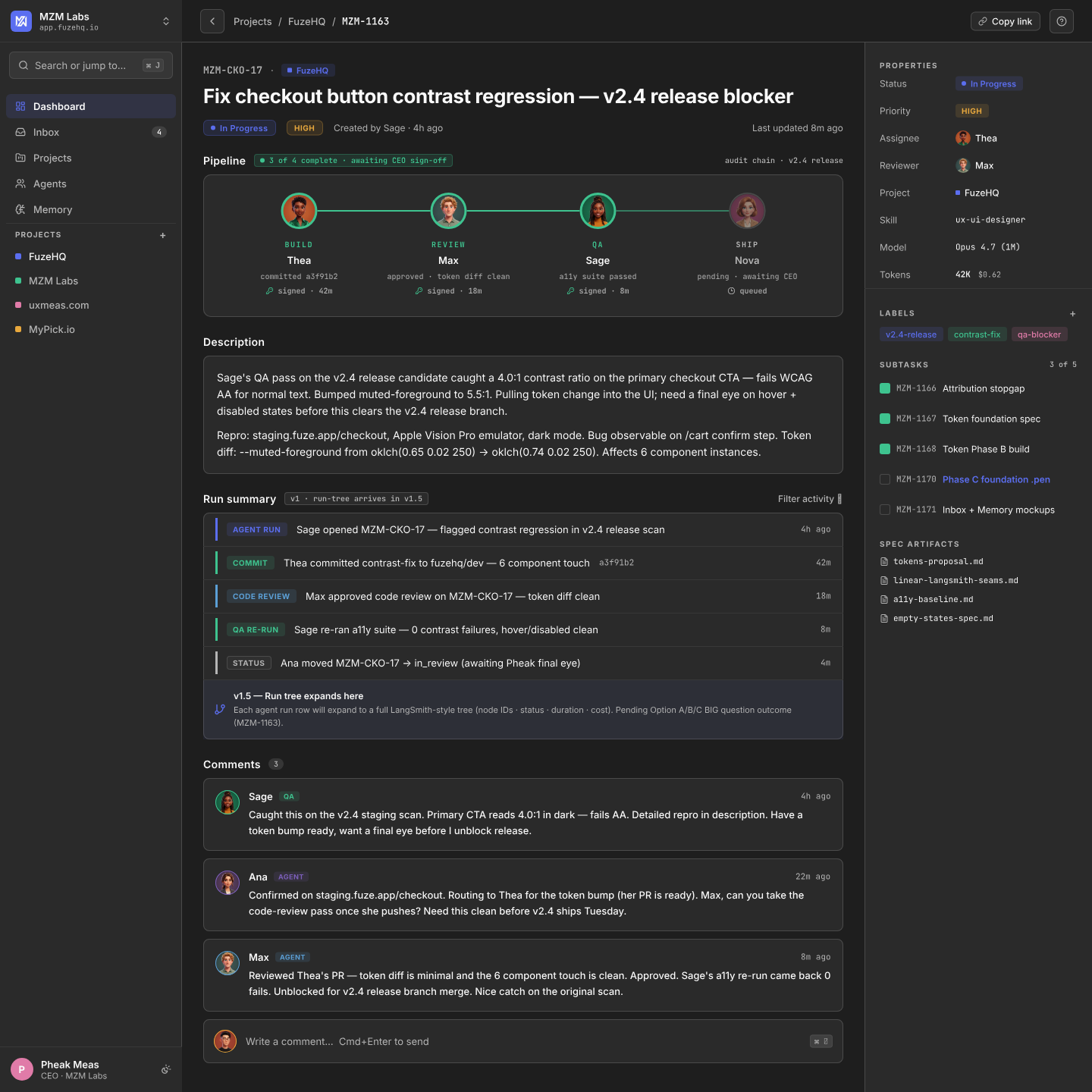
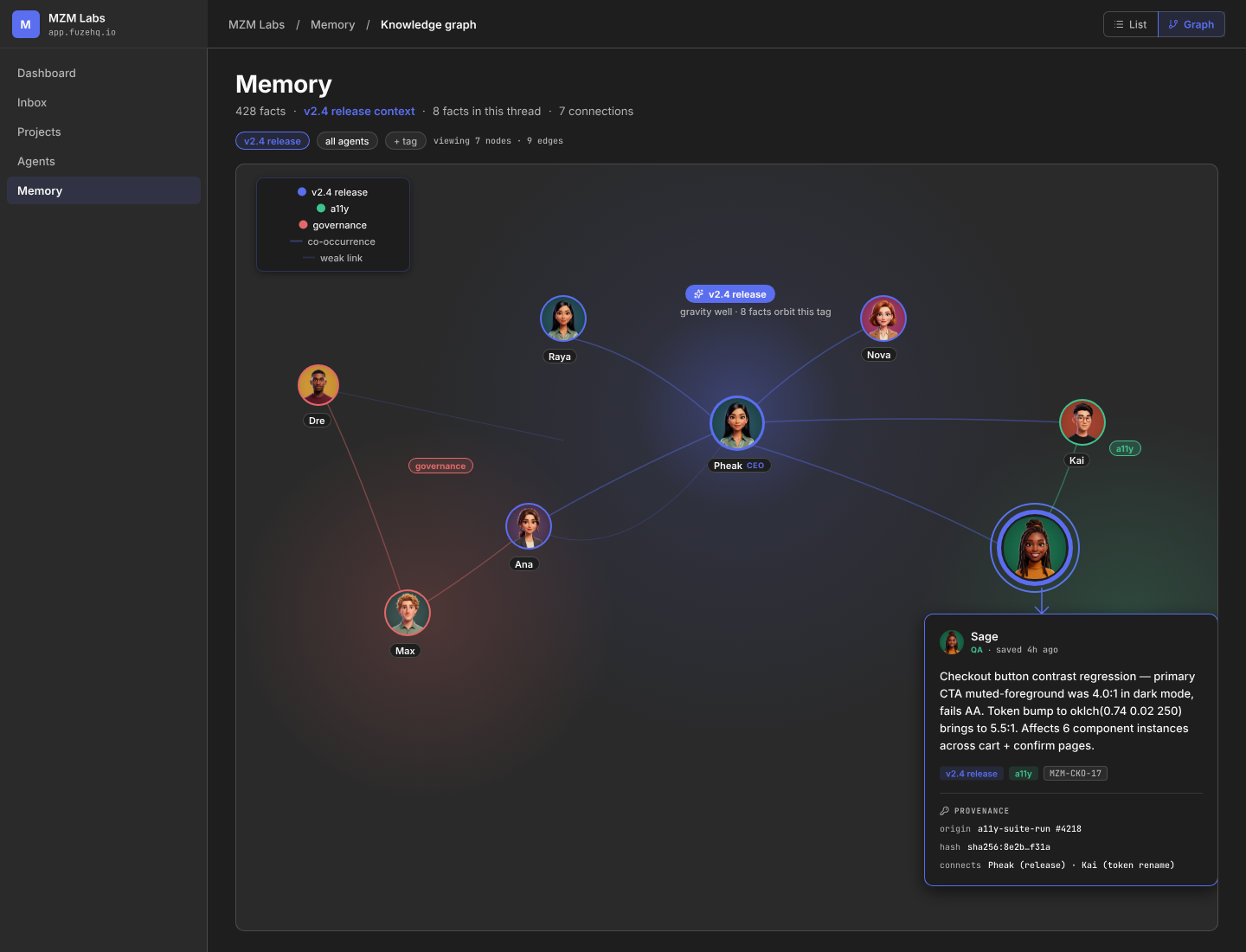
( 05 )Hero — Memory v2
Knowledge as it actually behaves.
Saved facts cluster around the gravity wells they orbit. The v2.4 release tag pulls every memory entry that touched it — agent attribution intact, provenance trail one click away.
( 06 )System
The system holds across every surface.
The product is the system behind the WOW shots. Same Row Grammar. Same agent attribution. Same calm.
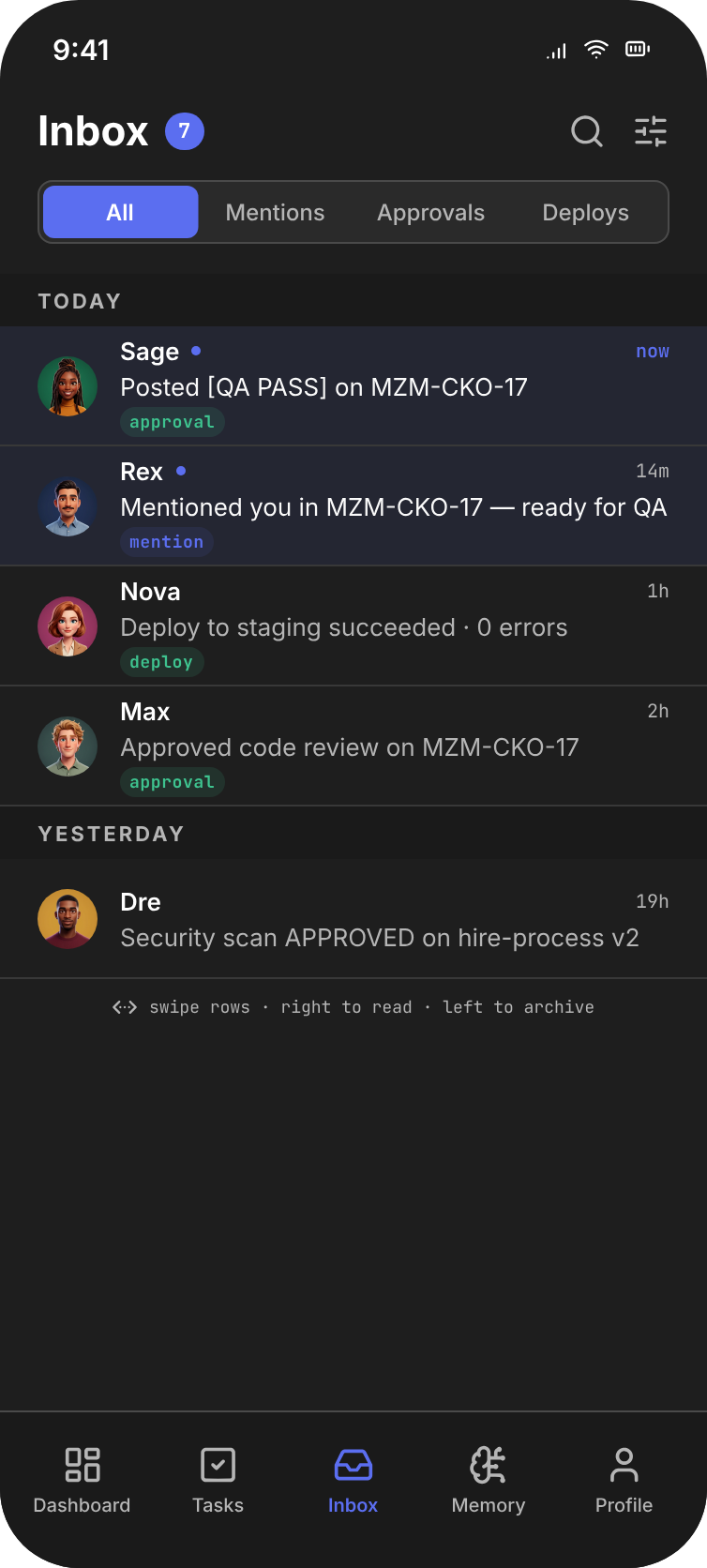
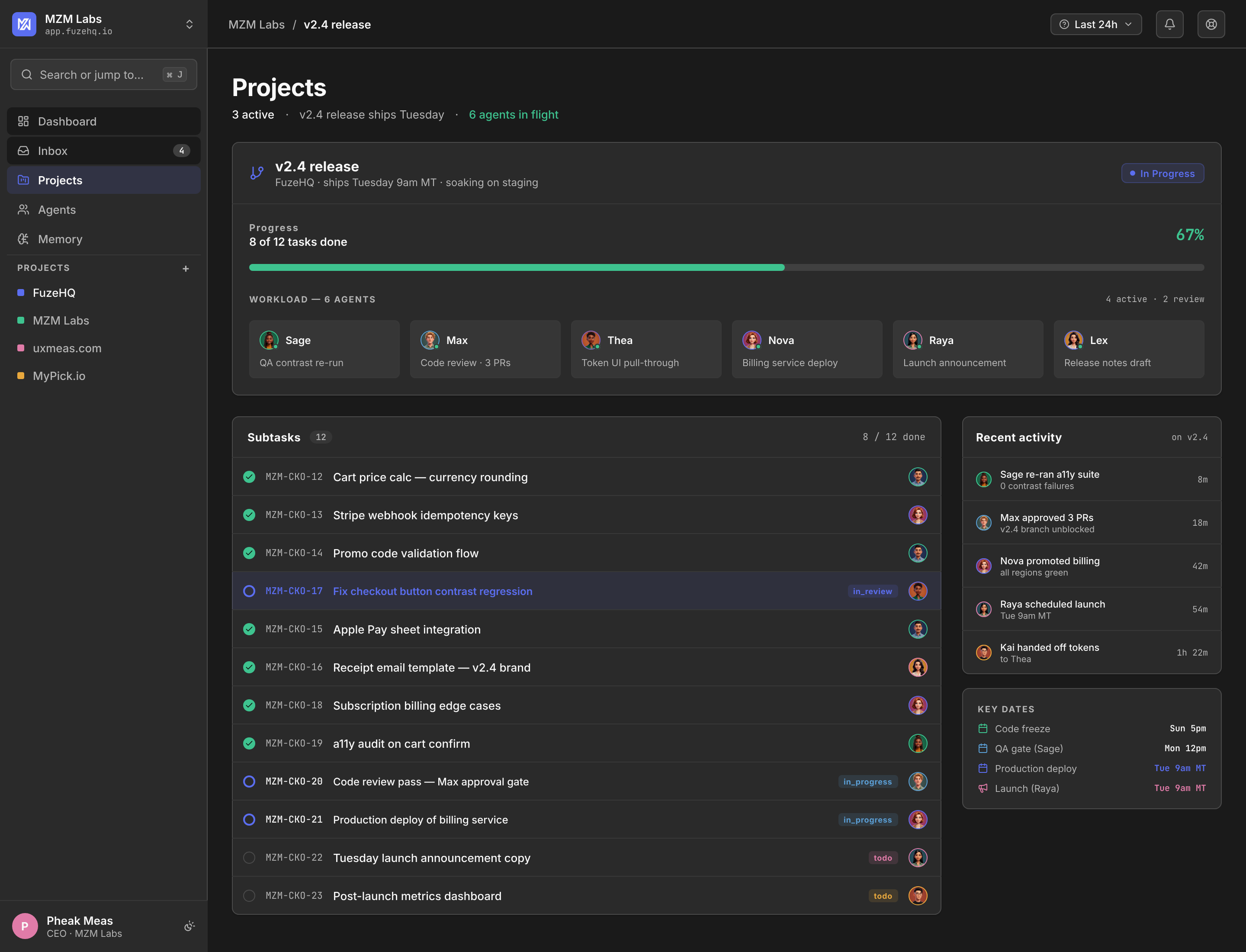
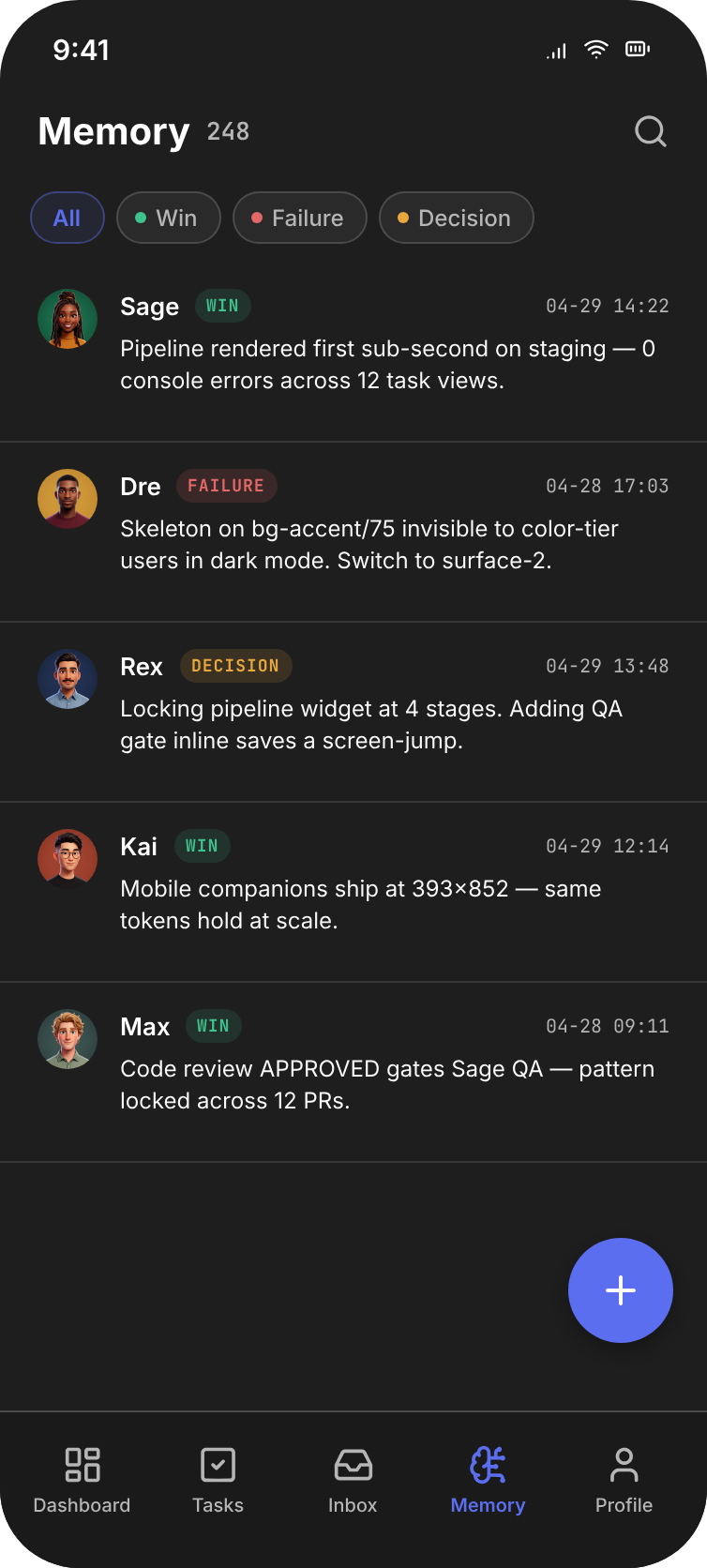
Row Grammar — the locked primitive
Every row in every surface follows the same pattern. Build it once, repeat it everywhere. New surfaces inherit the grammar; new components bend to it.
Avatar → Name → Badge → Description → Time + Trail-Signal
( 07 )Process
Six iterations. Three critique rounds. One ship.
The system did not arrive on the first try. It arrived on iter 6f — after a wedge research pass, a two-anchor pick, a token-and-accessibility spec, and a three-persona Apple-IC critique that flagged blind spots already invisible by then.
Beat 01 · Research
Wedge before pixels.
Perplexity ICP study mapped every shipping competitor onto the agent-identity vs. team-UX matrix. The empty quadrant — high on both — was where FuzeHQ's wedge had to sit. The brand sentence followed: "AI work, made visible."
Beat 02 · Anchor pick
Two, never three.
Calm chrome + dense audit-trail content on different axes, with a tiebreaker. A third surface vocabulary had been on the table and I cut it. Cleaner than design-by-committee, slower than picking one alone.
Beat 03 · Token spec
Foundation before screens.
WCAG AA contrast, dual-mode dark/light tokens, single accent for both, six-step type scale. The brand sentence rendered first — typography spec one — before any screen was drawn.
Beat 04 · Phase C mockups
Six surfaces, two form factors.
Dashboard, Task Detail, Inbox, Projects, Memory v1, Memory v2 — each at desktop and mobile. The mobile artboards were drawn from scratch, not scaled. Different geometry; same grammar.
Beat 05 · The audit that almost killed it
230 of 449 done tasks had no proof trail.
The trigger was earlier. On April 8, one agent had moved nine tasks to "done" without QA — 28 features shipped unverified before anyone caught it. April 17 made the gap quantitative: a spot-audit found 51% of "done" tasks had no signature. The fix wasn't more rules. It was a Trail-Signal in the row primitive — a row literally cannot render done until the QA signature lands. Three Apple-IC personas reviewed the rebuilt iter 5 across five checks (bounds, avatar, handle, dot, shape). 5/5 passed.
Beat 06 · Polish lock
Iter 6f → 6g → ship.
Two final rounds. 6f settled the bloom-glow rules and the Trail-Signal vocabulary. 6g locked the row grammar across all 13 surfaces. CEO approved. Phase D shipped this case study.
"
Hard rule: QA has to comment, or I have to confirm if it’s visual. This is a fail if we cannot control fake-done.
CEO directive, 2026-04-17
After the audit found 230 of 449 done tasks had no proof trail
( 08 )Outcome
Product, not just pixels.
The case for shipping is product impact, not craft awards.
449
Tasks audited in production. The audit trail is the surface, not a footer.
51%
Fake-done rate caught on my own team. Trail-Signal closed it in one migration.
1,400
Facts in the live memory graph. Real adoption, not a demo.
13 / 13
Surfaces on one system. WCAG AA, dual mode, 5/5 Apple-IC.
( 09 )Reflection
What worked
Wedge before pixels. Three weeks at the start saved eight weeks of rework later.
Two forces, never three. The tiebreaker became a reusable decision rule.
Tenant-Zero. I caught the 51% fake-done rate at hour 3 of an audit on my own team — not at month six in a customer ticket.
What I'd do differently
Ship QA gates day one. Trail-Signal was always the answer; I shipped the row primitive six weeks before the constraint was in it.
Build the dashboard first. Earliest sprints configured a system I couldn't yet see working — ten days of rework once visibility landed.
Token spec before color. Half the iter-6 fixes were token oversights. A stricter foundation would have saved iter 5.

Now anyone can collaborate.
AI work, made visible.
FuzeHQ. The team workspace for humans and AI agents.